This article is part of a series that provides practical advice and guidance on how to leverage the Continuous Architecture approach. All these articles are available on our “Continuous Architecture in Practice” blog. Here we conclude our discussion of a fictional implementation of the “Minimum Viable Architecture” concept that we started in our previous article[1].
Implementing a Chatbot
Step 4 -an “All-in-One” Chatbot
The team’s next challenge is to add to the capabilities of the chatbot to handle queries from exporters in addition to those from importers. They update the models, retrain them, and test them with their business customers.
This approach seems to work well initially since a single chatbot handles all user dialogs. However, some concerns quickly emerge. Both the NLU and Dialog Management models are rapidly growing in size, in terms of code and parameters. Training those models now takes several hours, even after small changes are made. Model deployment, including functional, security, and performance testing, also becomes a lengthy process. This is still manageable but it’s getting harder to implement new requests quickly.
The chatbot soon turns into a bottleneck. The models are becoming harder to maintain and train as they grow in size. Releasing new versions of the models is getting harder to schedule, as multiple stakeholders need to be satisfied with all the changes to the code and the parameters. Multiple team members are trying to update the models simultaneously, which creates version control issues. Business partners are getting unhappy with the delays in implementing their requests, so the team needs to rethink the architecture of their chatbot.
Step 5 – a Multi-Domain Chatbot
To better respond to the requests from their business partners, the team considers using a federated architecture approach for their chatbot. Using this model, the team would create three domain-specific chatbots, as follows:
- Chatbot – Importers
- Chatbot – Exporters
- Chatbot – FAQs
The three chatbots would each have their own NLU model, and training data. In addition to the three domain-specific chatbots, this architecture would need a routing mechanism to figure out which chatbot should handle a specific user request. One possibility would be to send each request to every chatbot and let it decide whether it can handle the request. Unfortunately, this could bring back the performance and scalability issues that the team solved earlier by implementing multiple chatbot instances. A better strategy would be to implement a “dispatcher” component responsible for evaluating each session request and deciding which chatbot should handle it. The dispatcher would be implemented as another chatbot that can handle user intents and take action by passing user information to the appropriate domain-specific chatbot.
The team evaluates the trade-offs between the current and proposed architectures as follows:
- Maintainability and adaptability vs. complexity: Splitting the “all in one” chatbot models into three smaller model sets would allow the team to respond faster to requests from their business partners. In addition, each chatbot would have its own, independent, and simpler deployment cycle using the federated architecture model. However, this approach would move complexity around within the chatbot architecture and may increase its fragility. For example, changes made to the open-source chatbot framework would have to be tested with each chatbot, and and applied to all of them. In addition, multiple sets of training data would need to be managed which complicates the data ingestion and transformation processes;
- Performance vs. complexity: Introducing a dispatcher component would improve the throughput of the chatbot, at the cost of increasing complexity since we would be adding a fourth chatbot and associated models to the architecture.
The team feels that the trade-offs are acceptable, and builds a simple prototype to test the proposed approach, including the dispatcher concept. This test is successful and the team decides to go ahead and implement the architecture depicted in the following diagram:
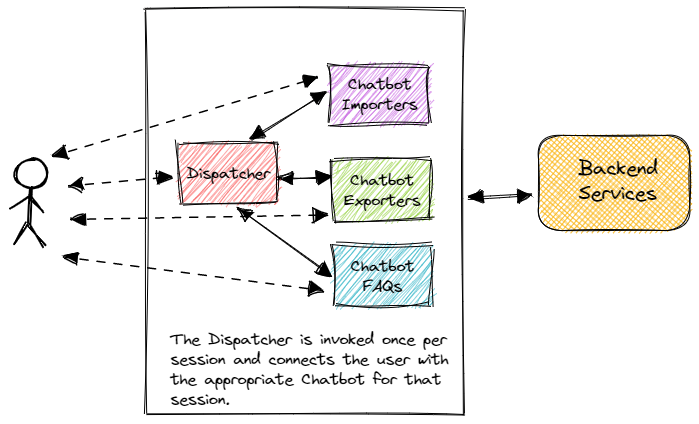
The federated architecture strategy turns out to be successful, and the chatbot users are pleased with the results.
Conclusion
Our two “Minimum Viable Architecture in Practice” articles described conceptually how we could use the MVA process to develop a simple chatbot that would handle some of the customer queries as part of a trade finance system. We treated this chatbot as an MVP that evolves and adapts to changing needs over time, which is an effective product development strategy. We created an MVA that helped us evaluate the technical viability of the MVP and provided a stable foundation that we can build upon as the product evolves. We made our architectural decisions transparent to help our stakeholders better understand why certain choices were made, which helps them make better decisions about how they can adjust the product to changing customer needs.
Limiting the budget spent on architecting is a good thing; it encourages us to think in terms of an MVA that starts with a small set of architectural decisions that the development team has made about the solution. This approach focuses on the sustainability of the solution which is only expanded when absolutely necessary. This prevents us from solving problems that may not exist for a long time, if ever, and from failing to anticipate a crippling challenge that may kill our product. Getting to an executable architectural design quickly and then continuously evolving that architecture is essential for modern applications.
As we move away from traditional application approaches involving large upfront architectural designs and evolve toward the rapid delivery of viable software products, we need to leverage MVPs and MVAs to support the continual delivery of those products sustainably.
[1] Minimum Viable Architecture In Practice (Part 1)
https://continuousarchitecture.com/2022/02/14/minimum-viable-architecture-in-practice-part-1/

Great read! Implementing a minimum viable architecture is crucial for efficient development. Your practical insights on prioritizing simplicity and flexibility resonate well. I appreciate how you emphasize adaptability and iterative improvements, making it clear that a dynamic approach is key. Looking forward to more practical tips on streamlining architecture in future posts!
LikeLike
Your practical approach and real-world examples make complex architectural concepts accessible to all. Looking forward to implementing these strategies in our own projects to achieve greater efficiency and adaptability. Keep up the excellent work
LikeLike